In this article, we'll explore how sequencing evolved from early manual chemistry to today’s long-read, AI-powered, and single-cell approaches, with real research examples you can dig into.
The Early Days: Chemical Sequencing and the Sanger Breakthrough
The story of sequencing starts in the 1970s. Before that, even though Watson and Crick had described the double helix in 1953, there was no way to read the actual order of bases in DNA.
Maxam–Gilbert sequencing (1977) was one of the first approaches, relying on chemical cleavage of DNA at specific bases. While innovative, it was laborious and hazardous, limiting its use.
Then came Frederick Sanger, who revolutionized the field with his chain-termination method (1977). In this approach, DNA is copied in vitro using special dideoxynucleotides that stop replication at specific bases. By separating the resulting fragments via gel or capillary electrophoresis, scientists could "read" the DNA sequence letter by letter with remarkable accuracy.
This method was so reliable it became the backbone of the monumental Human Genome Project, which ran from 1990 to 2003. It cost over $2 billion and took more than a decade, but produced the first complete human genome reference transforming biology forever.
Even today, Sanger sequencing remains the gold standard for targeted validation work because of its extraordinary accuracy.
The NGS Revolution: Reading Millions of Fragments at Once
While Sanger sequencing was a landmark, it was too slow and expensive for large-scale projects. Scientists needed a faster, cheaper way to sequence millions of DNA fragments at once.
This gave rise to Next-Generation Sequencing (NGS) in the mid-2000s. Unlike Sanger’s one-read-at-a-time approach, NGS uses massively parallel sequencing to read billions of fragments simultaneously.
Early commercial systems included 454 Pyrosequencing, which used light signals when bases were added, and SOLiD sequencing, which relied on a ligation-based approach with color-space encoding. Both advanced the field but had their own limitations, like homopolymer errors or complex data interpretation.
The real breakthrough came with Illumina’s sequencing-by-synthesis technology, which became the dominant platform for NGS. DNA fragments are attached to a flow cell, amplified into clusters, and then read one base at a time using fluorescent reversible terminators. Illumina sequencing is remarkably accurate, cost-effective, and scalable.
Today, Illumina offers a full range of systems from benchtop sequencers for targeted panels to high-throughput systems for population-scale projects (Illumina Systems Overview, Illumina Homepage).
NGS has revolutionized not just genomics but:
- Transcriptomics via RNA-Seq
- Epigenomics via bisulfite sequencing
- Metagenomics for studying entire microbial communities
- Clinical oncology, for personalized cancer profiling (PMC11080611)
- Rare disease diagnostics, ending diagnostic odysseys for patients (PMC11981433)
As this review on NGS notes, the approach is faster, cheaper, and more scalable than anything that came before.
Yet NGS typically produces short reads (100–300 bases), making it hard to assemble repetitive regions or resolve large structural variants. These limitations led to the development of third-generation sequencing.
Long Reads and Real-Time Analysis: The Third Generation
Third-generation sequencing solves the short-read problem by producing long or ultra-long reads that can span repetitive regions or structural variants in one go.
Pacific Biosciences (PacBio) pioneered Single-Molecule Real-Time (SMRT) sequencing. Their systems watch a DNA polymerase in real time as it copies DNA in tiny observation chambers called zero-mode waveguides. Early reads had high error rates but were long 10–20 kb on average. PacBio’s HiFi sequencing now combines these long reads with extremely high accuracy (>99.9%) (PacBio Website).
PacBio excels at:
- Detecting structural variants
- Phasing haplotypes
- Sequencing full-length transcript isoforms for better understanding of alternative splicing
Oxford Nanopore Technologies (ONT) introduced another game-changing approach. DNA strands are passed through protein nanopores in a membrane. As they pass, they change the ionic current, which is measured to determine the sequence even detecting modified bases like methylation.
ONT’s devices range from the portable MinION (USB-sized) to the high-throughput PromethION for large projects (Nanopore Technologies). Nanopore sequencing enables real-time, field-deployable sequencing, with read lengths sometimes exceeding a million bases.
These innovations have transformed:
- De novo genome assembly
- Structural variant detection
- Metagenomic profiling of uncultured microbes
- Real-time pathogen surveillance (as used during COVID-19 outbreaks, see PMC12106117)
- High-quality plant genome sequencing for food security (PMC12095160)
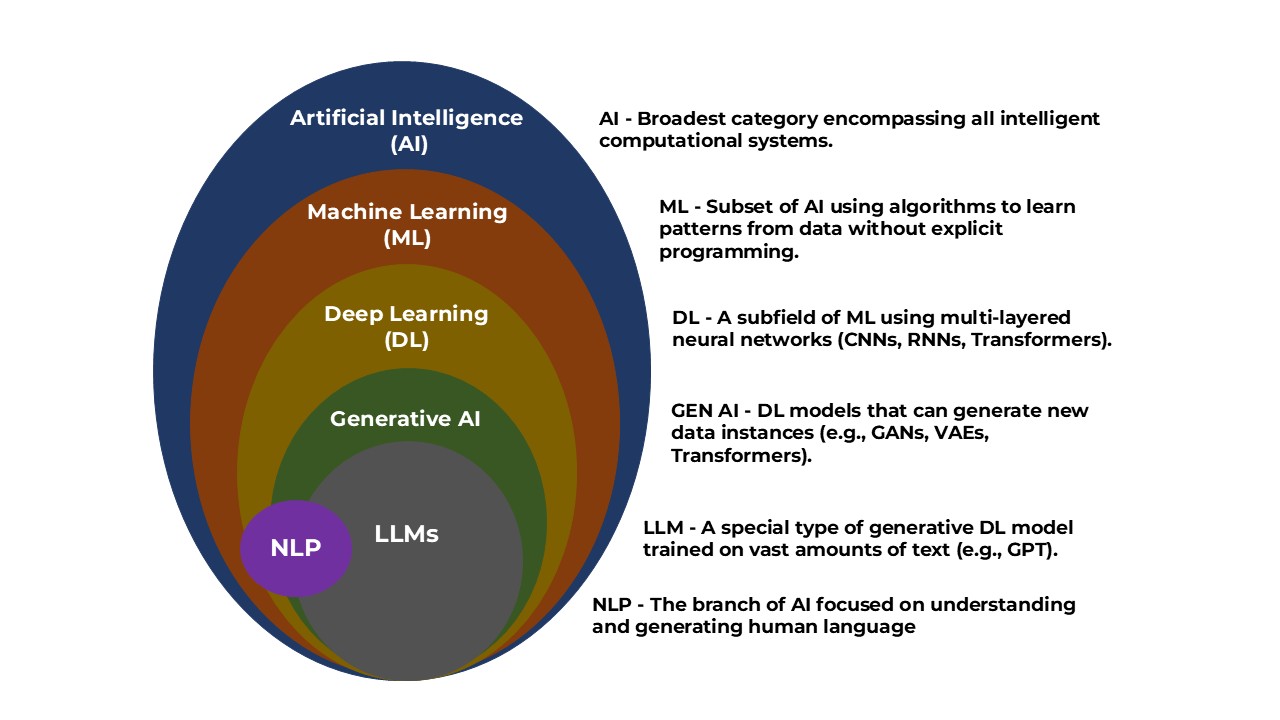
Variant Calling, AI, and the Era of Big Data
Sequencing is just the first step. The real challenge is making sense of the data.
Variant calling identifying SNPs and indels is critical for understanding disease risk. This has seen huge improvements with tools like DeepVariant, which uses deep neural networks to deliver highly accurate variant calls even from noisy data (Google Research on DeepVariant, PubMed Review on Variant Calling).
AI and machine learning have become essential tools for interpreting sequencing data. As this review on deep learning in human genomics explains, models can help classify variants, predict functional effects, and find patterns invisible to traditional analyses.
Healthcare systems are also thinking deeply about the challenges of integrating genomics into care, from data privacy to health equity (PMC3900115, Genomic Medicine Editorial).
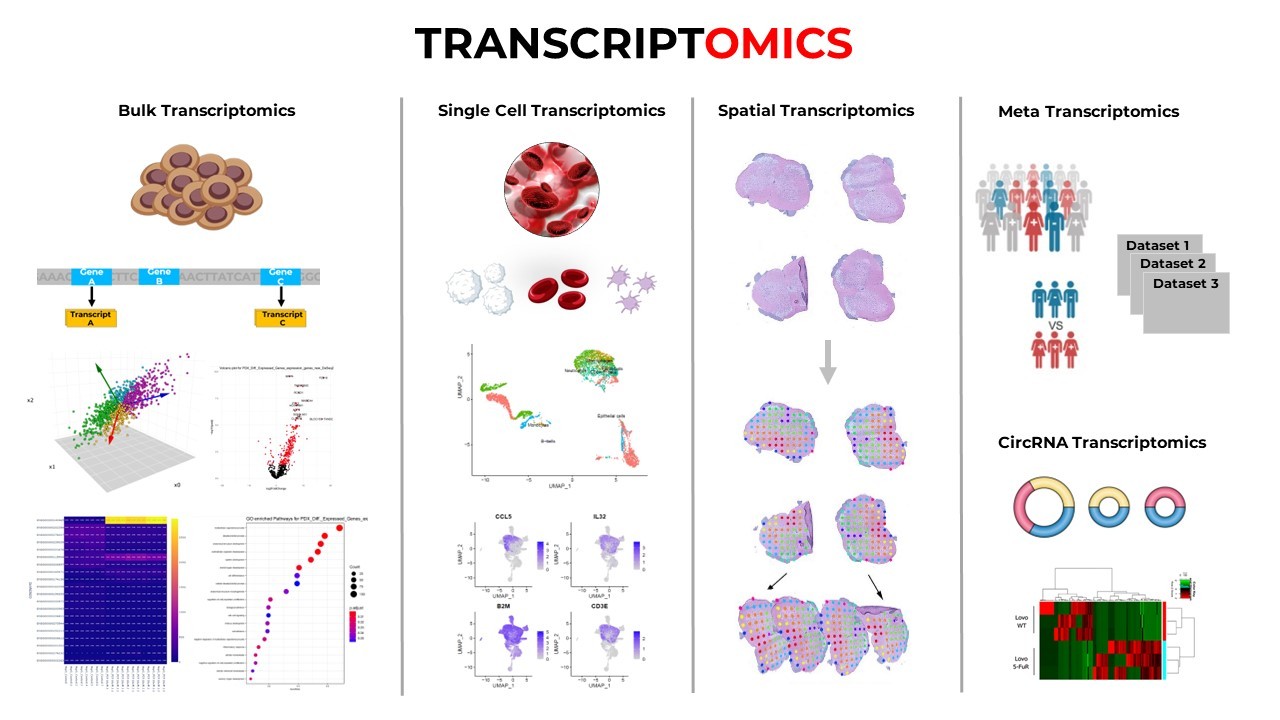
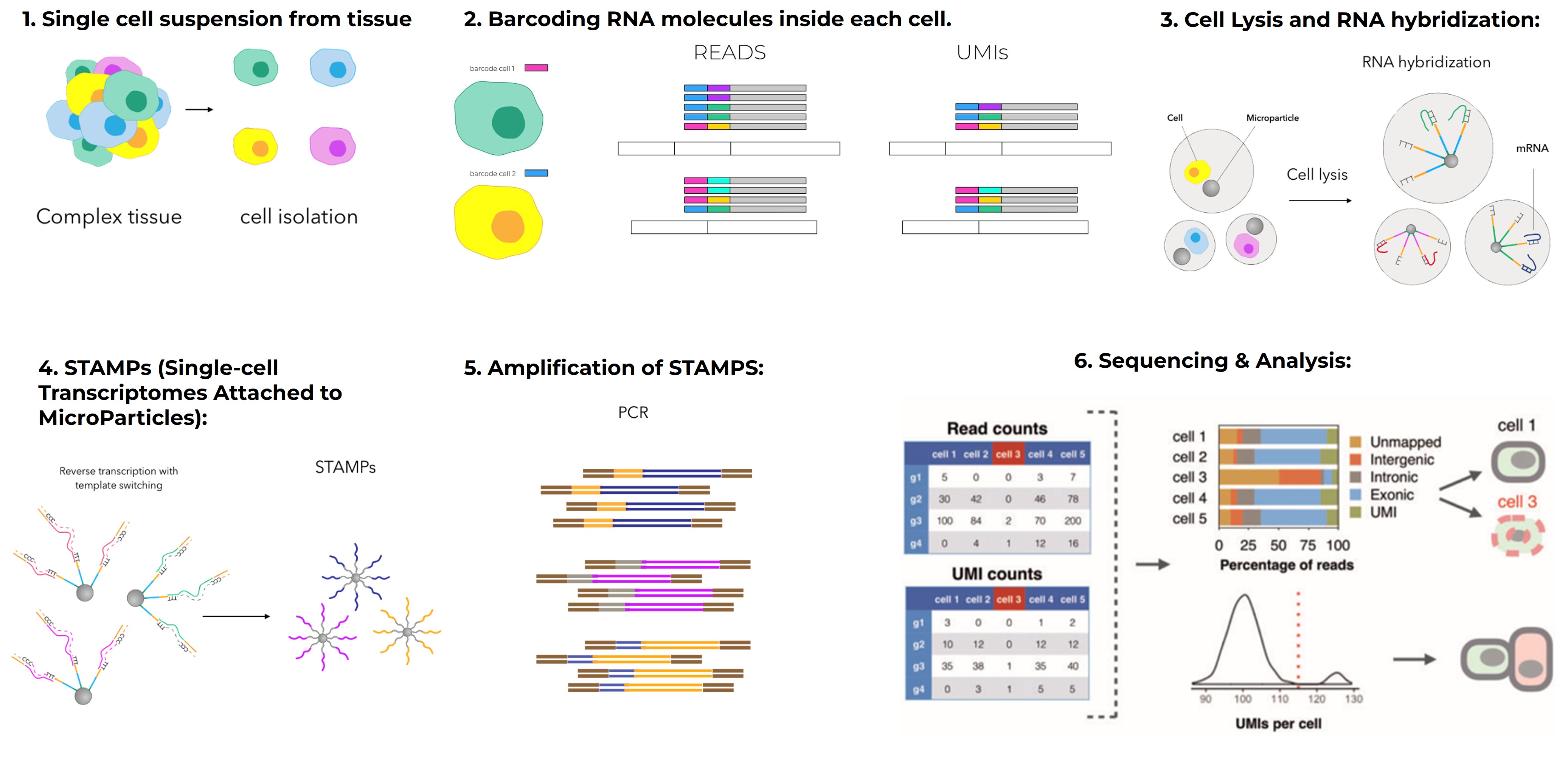
Single-Cell and Spatial Genomics: The Next Frontier
Sequencing has also gone single-cell. Technologies now let us profile gene expression in thousands of individual cells at once, revealing cell types, states, and developmental trajectories.
Projects like the Human Cell Atlas aim to map every cell type in the human body. This kind of data is freely accessible for research, with tools to help scientists analyze it (Human Cell Atlas Help).
Single-cell sequencing has transformed our understanding of development, cancer heterogeneity, and immune responses, among many other fields.
EVOLVING METHODOLOGIES
It’s worth remembering the methods that have shaped sequencing’s journey:
- Maxam–Gilbert: Chemical cleavage, largely obsolete.
- Sanger: Chain-termination, still used for validation.
- 454 Pyrosequencing: Early NGS, light-based detection.
- SOLiD: Ligation-based with color-space encoding.
- Illumina: Short-read sequencing-by-synthesis, dominant NGS method.
- Ion Torrent: Semiconductor pH detection.
- PacBio SMRT: Long, accurate single-molecule reads.
- Oxford Nanopore: Ultra-long, portable, real-time reads.
Each innovation expanded what questions could be answered from discovering new species in the microbiome (MDPI Review) to tailoring cancer treatments to the mutations in a tumor (PMC11080611).
Why It Matters ?
Sequencing has become essential in:
- Precision medicine: tailoring treatments to individual genomes
- Rare disease diagnosis: ending diagnostic odysseys
- Public health: tracking pathogen evolution
- Agriculture: breeding crops for sustainability
- Biodiversity: conserving endangered species
Initiatives like the All of Us Research Program aim to make sure these benefits reach everyone, by including diverse populations in genomic research.
Looking Ahead
From the first chemical methods to today’s AI-enhanced, real-time, single-cell approaches, sequencing has come incredibly far. Costs have fallen from billions to hundreds of dollars. Accuracy has soared. And we’re now able to integrate genomics with transcriptomics, epigenomics, metagenomics, and proteomics to create a holistic view of life.
As AI keeps improving and costs continue to drop, sequencing is becoming routine in medicine, agriculture, and conservation. It’s no longer just a lab technique-it’s a cornerstone of modern science.